
DataSift Launches Vedo To Help Enterprises Channel The Big Social Data Firehose

DataSift has built a reputation as a provider of Twitter, Facebook and Tumblr firehoses — streams of unstructured data from those and dozens of other social sources, which can then be used in applications to track larger user sentiment and other trends. Today, DataSift is ramping up its presence in the big data game with the launch of Vedo, a processing engine that automates some of those functions usually performed by data scientists to make sense of that firehose data.
Co-founder/CTO Nick Halstead tells me that “Vedo” comes from the Italian “I see,” suggested by DataSift’s chief technical architect Lorenzo Alberton, who helped devise the service, its first major product offering on top of its data services.
With DataSift announcing a $42 million round of funding just earlier this month, Vedo underscores the company’s intention to use some of that financing to expand its products and specifically sharpen its target on the enterprise market. Vedo has been a year in the making, he says.
Halstead tells me that the idea behind Vedo is to offer data processing companies (Simply Measured being one example), enterprises, brands, app developers and other customers an easy way of “reading” the data that comes out of DataSift. “We’ve been very good at curating and identifying rules to get to the right data,” Halstead says, “but a lot of that has been really simplistic.”
Now, DataSift will effectively offer customers three ways of tapping into data, by way of Vedo. Social tech app developers, Halstead says, are likely to have in-house data scientists who will be able to use the extensions from Vedo to add machine learning to their existing applications, resulting in faster development. “Similar to how our single API have lowered their costs, this will help them enhance machine learning but with much lower cost,” he says.
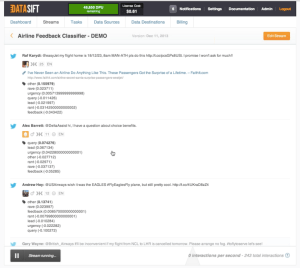 Enterprise customers, he continues, are likely to want a bit more structure in how they interact with DataSift data.
Enterprise customers, he continues, are likely to want a bit more structure in how they interact with DataSift data.
For them, the company has created pre-made classifications and taxonomies, which will be available in a library and will continue to be enhanced and improved. Among the examples Halstead showed me here were feeds that, for example, identified what devices and applications people are using to post to Twitter — there are 80,000 sources in all in this one (!) — and a feed that aggregated all airline-related tweets, which can then be classified into different categories like questions, gripes, praise and so on. Yes, all those United and Easyjet complaints, all in one place.
The third area is in the area of professional services, where DataSift will effectively let you outsource your data manipulation to its own in-house team of data scientists and consultants. “If there is some kind of machine learning you want to do and you don’t have your own data scientists, we will go off and build that for you,” he says.
All in all, Halstead says that DataSift did all of this to some extent in the past — indeed, it has already been providing dozens of different kinds of metatags on data “to help customers understand social,” in Halstead’s words. “But this takes it into a different league.”
The move to offer Vedo points to another big trend we’ve been seeing in enterprise: the larger push to harness and shape the nebulous “big data” promise. DataSift notes a forecast from IDC that predicts that by 2020, one-third of the “data in the digital universe”, which amounts to over 13,000 exabytes, will have big data value. But it will remain meaningless without some sort of conduits to channel it in a particular direction.
Pricing, Halstead says, will come under the existing model that DataSift uses for firehose services, where costs vary depending on size and complexity of what’s being requested. Those current packages start at around $1,000/per month.
Photo: Flickr
